



Современный Интернет предлагает безграничные возможности для распространения информации. Однако, в некоторых случаях, есть необходимость скрыть свой сайт от поисковых систем и ограничить доступ к нему. Это может быть полезно, когда владельцу сайта требуется соблюсти конфиденциальность данных или просто сохранить сайт для себя.
Для того чтобы закрыть сайт от индексации и отображения в результатах поиска следует использовать различные меры. В первую очередь, можно запретить поисковым системам индексировать страницы сайта с помощью использования файла robots.txt. Этот файл содержит инструкции для поисковых систем и позволяет указать, какие страницы должны быть индексированы, а какие нет.
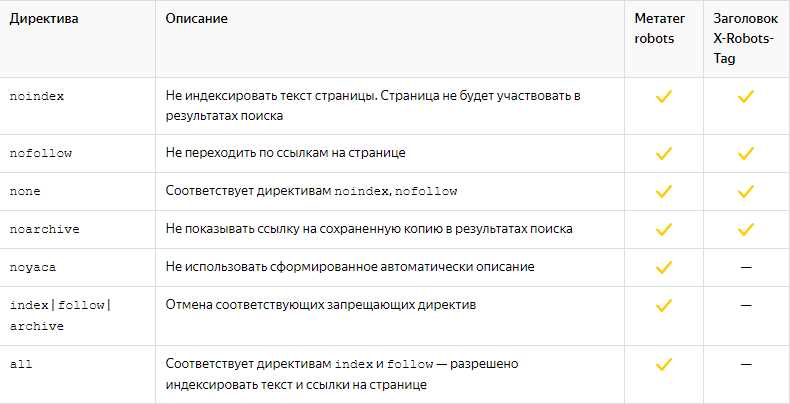
Кроме того, для дополнительной защиты можно использовать мета-теги noindex и nofollow. Они указывают поисковым системам не индексировать страницы сайта и не следовать по ссылкам на них. Также стоит учесть, что закрытие сайта от индексации можно осуществить с помощью файлов .htaccess или настройкой доступа на сервере.
Важно отметить, что показания поисковым системам ожидаемого поведения (например, с помощью мета-тега noindex) не являются обязательными, и некоторые поисковые системы могут игнорировать эти инструкции. Поэтому дополнительные меры безопасности, такие как авторизация пользователя или защита паролем, также могут быть необходимы для полной безопасности сайта.
Роботы.txt: ограничение доступа поисковиков к сайту
В файле robots.txt можно указать различные инструкции для разных поисковых систем, используя их идентификаторы. Например, можно разрешить индексацию всем поисковым системам, а запретить только конкретному роботу.
Файл robots.txt имеет простую структуру. Обычно он состоит из нескольких «User-agent» блоков, которые определяются идентификаторами поисковых роботов, и «Disallow» директив, которые указывают путь к страницам, которые запрещено индексировать.
Директивы для запрета доступа к определенным страницам указываются с помощью ключевого слова «Disallow», за которым следует путь к странице или каталогу. Например, «Disallow: /private/» запретит доступ к любому содержимому, находящемуся в каталоге «private».
Также в файле robots.txt можно указать путь к карте сайта, используя директиву «Sitemap». Такой путь используется поисковыми роботами для обнаружения и индексации страниц сайта.
Пример robots.txt файла:

User-agent: *
Disallow: /private/
Disallow: /admin/
Allow: /public/
Sitemap: https://example.com/sitemap.xml
В этом примере разрешается индексация большинству поисковых роботов, кроме указанных в отдельных блоках «Disallow» директивой. В каталогах «private» и «admin» индексация запрещена, а в каталоге «public» разрешена. Также указан путь к карте сайта по директиве «Sitemap».
Использование файла robots.txt позволяет управлять доступом поисковых роботов к вашему сайту и помогает в защите конфиденциальной информации или ограничении доступа к определенным разделам сайта.
Метатеги noindex и nofollow: запрет индексации и перехода по ссылкам

<meta name="robots" content="noindex">
Метатег nofollow указывает поисковым системам, что они не должны переходить по ссылкам, находящимся на данной странице. Это может быть полезно, если, например, вы хотите, чтобы поисковые системы не учитывали ссылки на определенные внутренние или внешние страницы. Для этого добавьте следующий код:
<meta name="robots" content="nofollow">
Также можно комбинировать метатеги noindex и nofollow, указав их вместе:
<meta name="robots" content="noindex, nofollow">
Это запретит поисковым системам индексировать данную страницу и переходить по ссылкам на ней. Учитывайте, что эти метатеги не дают 100% гарантию на то, что поисковые системы не проиндексируют или не перейдут по ссылкам, но в большинстве случаев они будут следовать этим указаниям.
Файл sitemap.xml: управление индексацией страниц
Задача sitemap.xml состоит в том, чтобы дать поисковой системе сводку о структуре сайта, а также указать наиболее важные страницы для индексации. Файл sitemap.xml должен быть создан в корневой директории сайта и доступен для чтения поисковым системам.
Структура файла sitemap.xml:
- urlset: Объявление главного элемента, содержащего список URL-адресов страниц.
- url: Каждая страница сайта должна быть представлена внутри этого элемента.
- loc: URL-адрес страницы
- lastmod: Дата последнего изменения страницы
- changefreq: Частота изменений страницы (например, always, hourly, daily, weekly)
- priority: Приоритет страницы относительно других страниц на сайте (от 0,0 до 1,0)
Важно поддерживать sitemap.xml актуальным и обновлять его при добавлении новых страниц или изменении структуры сайта. Это позволяет поисковым системам более эффективно индексировать новый контент и отображать его в результатах поиска.
Загрузка файла sitemap.xml в поисковую систему происходит через Google Search Console или аналогичные инструменты других поисковых систем. После загрузки файла, поисковая система будет регулярно проверять его на обновления и использовать информацию для правильной индексации сайта.